Cloud server scaling is the process of adjusting computing resources to match application demand — adding resources when traffic increases and potentially reducing resources when demand decreases. Understanding scaling strategies is essential for organizations running cloud-hosted applications, as proper scaling ensures application performance and availability while optimizing infrastructure costs. The two fundamental scaling approaches — vertical scaling (scaling up) and horizontal scaling (scaling out) — provide different benefits, limitations, and implementation complexities that influence which approach is appropriate for specific application architectures and workload patterns.
This guide examines both vertical and horizontal scaling methods in depth, covering implementation approaches, advantages, limitations, cost implications, and best practices for cloud infrastructure scaling. The analysis provides practical, actionable information for system administrators, DevOps engineers, and developers implementing scaling strategies on cloud platforms including DigitalOcean, Linode, Vultr, AWS, Google Cloud, and Azure.
Vertical Scaling (Scaling Up)
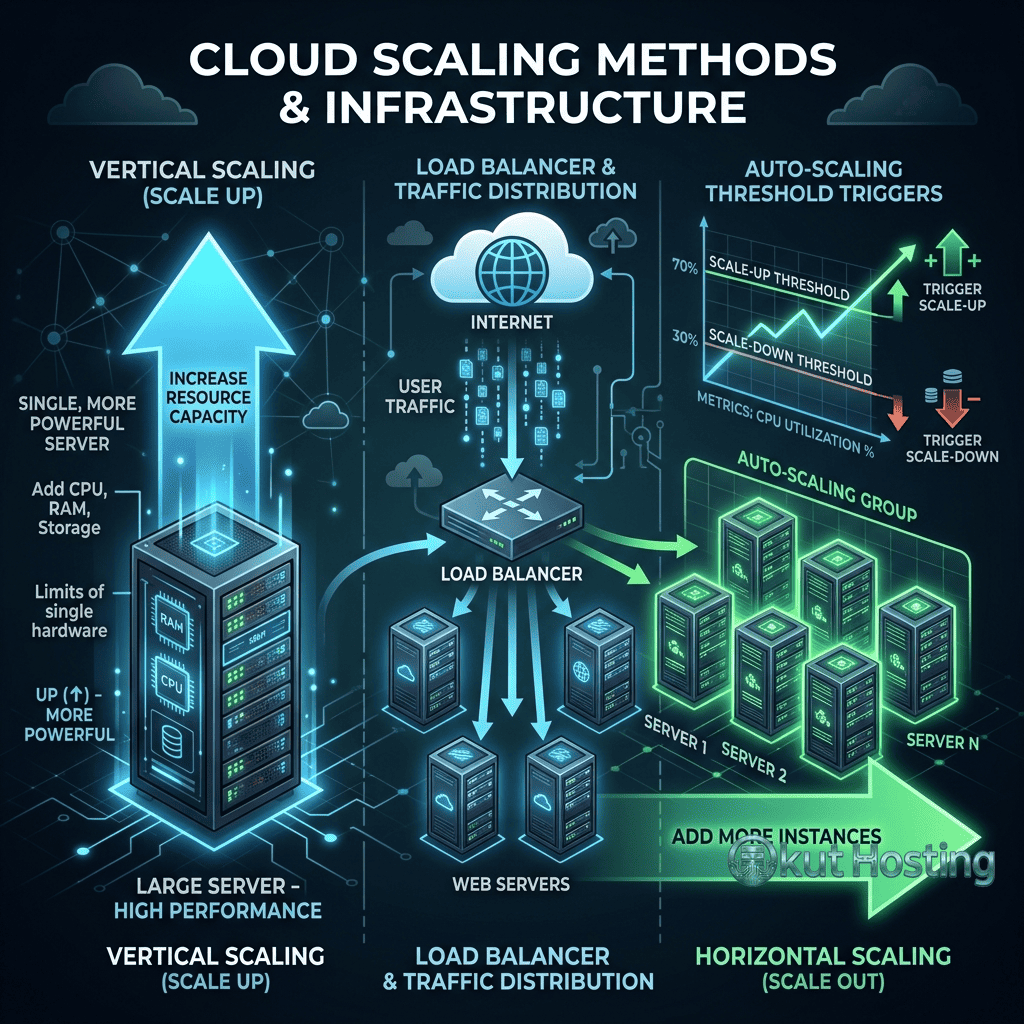
Vertical scaling involves increasing the resources (CPU, memory, storage) of an existing server to handle increased workload demands. This is the simplest scaling approach — when the current server becomes insufficient, upgrade it to a larger instance with more powerful hardware. Most cloud platforms enable vertical scaling through instance resizing, where the server is upgraded to a larger plan with more vCPUs, RAM, and storage capacity.
The primary advantage of vertical scaling is its simplicity. The application architecture does not need to change — the same application running on a single server simply receives more resources. Database configurations, file storage, application code, and networking remain unchanged. This simplicity makes vertical scaling the preferred initial scaling approach for most applications, particularly monolithic applications that were not designed for distributed execution.
Vertical scaling limitations include: a physical ceiling on maximum server size (the largest available instance defines the maximum vertical scale); potential downtime during resize operations (some platforms require server restart for resource changes); and single point of failure (the application still runs on a single server, so server failure causes complete application outage). These limitations make vertical scaling suitable and practical as an initial scaling approach but ultimately insufficient as the sole scaling strategy for growing applications.
Vertical Scaling Implementation
On most cloud platforms, vertical scaling involves selecting a larger instance size through the management console or API. The process typically requires a brief planned server restart or reboot to apply the new resource allocation. Some advanced platforms support live resource adjustment (hot-add) for CPU and memory without restart, though this capability varies by provider and instance type.
When vertically scaling a server, several configuration adjustments may be needed: database buffer pool sizes should be increased to utilize additional memory; web server worker processes should be adjusted for additional CPU cores; PHP-FPM pool sizes should be updated for increased memory availability; and caching systems should be reconfigured to leverage larger memory allocations. Without these configuration adjustments, the application may not fully utilize the additional resources provided by the larger instance.
Horizontal Scaling (Scaling Out)
Horizontal scaling involves adding additional servers to distribute workload across multiple instances rather than increasing the size of a single server. This approach requires a load balancer to distribute incoming traffic across the server pool, shared or replicated storage for consistent data access, and application architecture that supports distributed execution across multiple servers.
The advantages of horizontal scaling are significant: there is no practical ceiling on capacity (additional servers can be added indefinitely); redundancy is inherent (if one server fails, others continue serving traffic); and resource costs scale linearly with demand. Horizontal scaling provides the essential foundation for highly available production architectures that can effectively handle sudden traffic spikes, unexpected server failures, geographic distribution of workloads.
Horizontal scaling limitations include: architectural complexity (applications must support distributed execution); session management challenges (user sessions must be shared or centralized across servers); data consistency requirements (databases, file systems, and user-generated content must be accessible from all servers); and operational complexity (managing multiple servers requires more sophisticated infrastructure management). These complexities make horizontal scaling more challenging to implement but essential for applications that outgrow vertical scaling capacity.
Load Balancing
Load balancers are the essential component that enables horizontal scaling by distributing incoming traffic across multiple backend servers. Load balancing algorithms determine how traffic is distributed: round-robin distributes requests sequentially across servers; least-connections routes traffic to the server with the fewest active connections; IP-hash routes clients consistently to the same server based on IP address; and weighted distribution allocates proportional traffic based on server capacity.
Cloud platforms provide managed load balancer services: DigitalOcean Load Balancers, Linode NodeBalancers, Vultr Load Balancers, AWS Elastic Load Balancing, Google Cloud Load Balancing, and Azure Load Balancer. Managed load balancers automatically handle provisioning, configuration, health checking, SSL/TLS termination, and certificate management, simplifying horizontal scaling implementation. Self-managed load balancers using Nginx, HAProxy, or Traefik provide more configuration control but require manual management.
Health checking ensures that load balancers only route traffic to healthy backend servers. HTTP health checks verify that the application responds correctly. TCP health checks verify that the server is accepting connections. Failed health checks automatically remove unhealthy servers from the traffic rotation, providing automatic fault tolerance.
Database Scaling
Database scaling is often the most challenging aspect of application scaling because databases manage state that must remain consistent across all application instances. Database scaling approaches include: vertical scaling (larger database instance); read replicas (copies of the database that serve read queries, reducing load on the primary database); connection pooling (efficiently reducing database connection overhead); query optimization (reducing query execution time); and database sharding (distributing data across multiple database instances based on partitioning logic).
Read replicas provide a practical first step in database scaling. Write operations go to the primary database, while read operations are distributed across replicas. Since most web applications and content management systems perform significantly more read operations than write operations, read replicas can dramatically increase database capacity. Managed database services on cloud platforms (DigitalOcean Managed Databases, Linode Managed Databases, AWS RDS, Google Cloud SQL) provide built-in read replica support with automated replication management.
Connection pooling through tools like PgBouncer (PostgreSQL) or ProxySQL (MySQL) reduces database connection overhead by maintaining persistent connections to the database that are shared across application processes. This reduces the database connection establishment overhead that becomes significant at high concurrency levels.
Session Management for Horizontal Scaling
When applications scale horizontally, user session data must be accessible from any server in the pool rather than stored locally on a single server. Session management approaches include: centralized session storage using Redis or Memcached (all servers read/write sessions to a shared cache); database-backed sessions (sessions stored in the shared database); sticky sessions (load balancer routes the same user to the same server); and stateless application design (session data encoded in client-side tokens like JWTs).
Redis-based session storage is the most common approach for horizontally scaled web applications. Redis provides fast, in-memory session storage with persistence options, supporting session access from any server in the pool. Most web frameworks (WordPress, Laravel, Django, Express.js) support Redis session backends with minimal configuration changes.
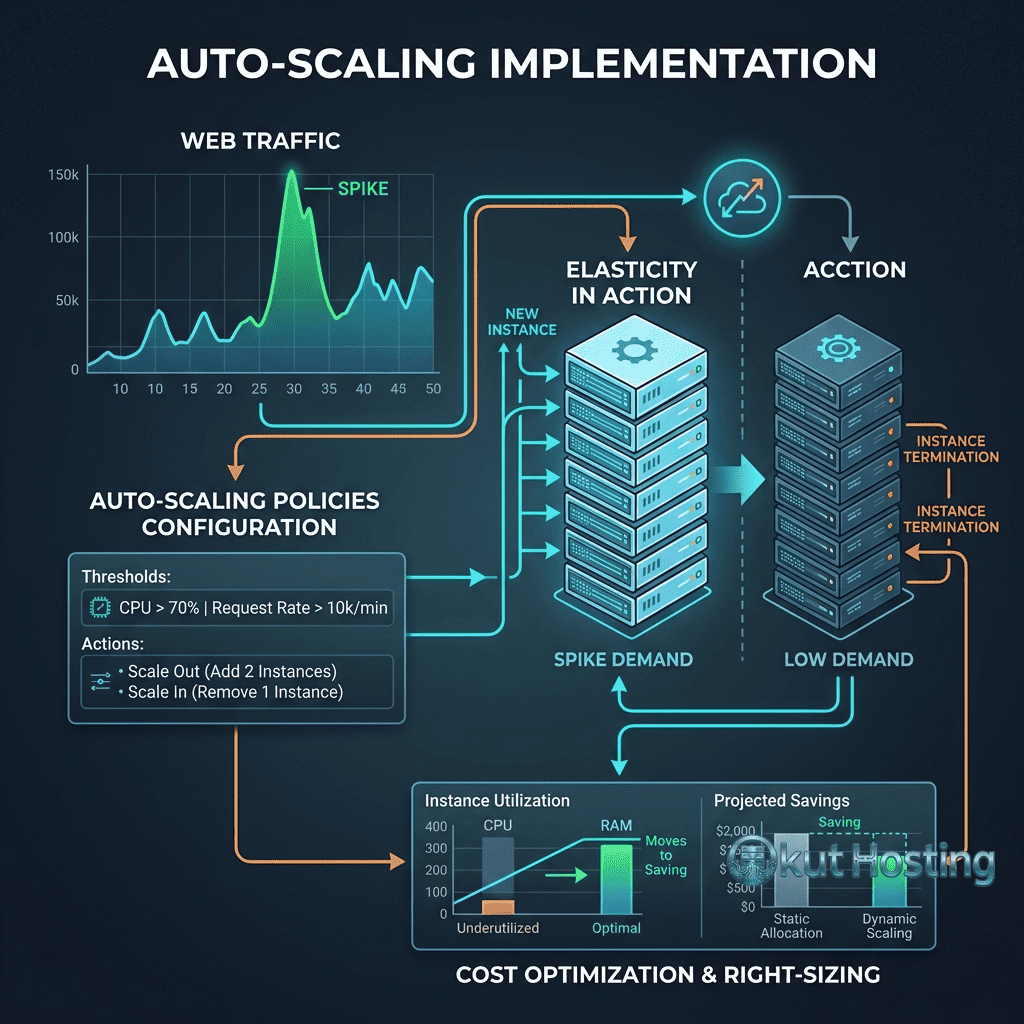
Auto-Scaling
Auto-scaling automatically adjusts the number of server instances based on real-time demand metrics. When traffic increases and resource utilization exceeds defined thresholds, auto-scaling adds additional instances to the server pool. When traffic decreases, auto-scaling removes excess instances to reduce costs. This fully automated scaling provides optimal resource utilization and cost efficiency without manual intervention.
Cloud platform auto-scaling services include: AWS Auto Scaling Groups, Google Cloud Managed Instance Groups, Azure VM Scale Sets, and Kubernetes Horizontal Pod Autoscaler (HPA). These services monitor configurable metrics (CPU utilization, memory usage, request count, custom metrics) and automatically adjust instance counts within defined minimum and maximum boundaries.
For independent cloud providers (DigitalOcean, Linode, Vultr) that do not provide native auto-scaling services, custom auto-scaling can be implemented using platform APIs combined with monitoring tools. Scripts or automation tools monitor resource utilization, and when thresholds are exceeded, API calls provision additional instances and register them with the load balancer. This approach requires more implementation effort but provides auto-scaling capability on any platform with API access.
Application Architecture for Scaling
Twelve-factor application design principles provide a framework for building applications that scale effectively. Key principles include: stateless processes (application state stored externally rather than on individual servers); shared-nothing architecture (each instance operates independently without shared state); configuration through environment variables (enabling instance-specific configuration); and disposable instances (servers can be created and destroyed without data loss).
Microservices architecture supports independent scaling of application components. Instead of scaling the entire application monolithically, individual services (user authentication, product catalog, order processing) scale independently based on their specific demand patterns. This granular scaling optimizes resource utilization by allocating resources where they are needed rather than scaling everything uniformly.
Caching Strategies for Scale
Caching reduces the load on backend servers and databases by serving frequently requested data from fast, in-memory storage. Multi-layer caching strategies include: CDN caching (static assets served from edge locations closest to users); reverse proxy caching (Nginx or Varnish caching dynamic page responses); application-level caching (Redis or Memcached storing computed results); and database query caching (frequently executed queries cached in memory).
Effective caching can reduce the scaling requirements significantly. A properly cached WordPress site, for example, might serve 90% or more of requests from cache without executing PHP code or database queries, effectively multiplying the capacity of each server by an order of magnitude compared to uncached configurations.
CDN and Geographic Scaling
Content Delivery Networks (CDNs) provide geographic scaling by distributing content across global edge locations. CDN caching serves static assets (images, CSS, JavaScript, fonts) from edge servers closest to users, reducing origin server load and improving page load times for geographically distant users. For applications with global audiences, CDN integration can reduce origin server traffic by 60-80%, deferring the need for compute scaling while improving global user experience.
Geographic scaling extends beyond CDN caching to deploying application instances in multiple geographic regions. Multi-region deployment serves users from servers geographically close to their location, reducing network latency and improving application responsiveness. DNS-based geographic routing directs users to the nearest application region. This approach requires data replication between regions and careful management of data consistency across all geographically distributed instances.
WordPress-Specific Scaling Strategies
WordPress scaling follows the general scaling principles but with WordPress-specific considerations. WordPress’s database-intensive architecture makes database scaling particularly important. Key WordPress scaling strategies include: page caching with Nginx FastCGI Cache or WP Super Cache (serving cached HTML pages without PHP execution); object caching with Redis (caching database query results in memory); media offloading to object storage (reducing local storage requirements and enabling shared media access); and database optimization through query monitoring and index optimization.
For horizontally scaled WordPress deployments, the wp-content/uploads directory must be accessible from all instances through shared storage (NFS) or object storage (S3-compatible). The WordPress database must be centralized or replicated across instances. Session management should use database or Redis-backed sessions instead of file-based sessions. Plugin compatibility with multi-server environments should be verified, as some plugins assume single-server deployment.
Failover and High Availability
Scaling architectures inherently support high availability by distributing workload across multiple servers. When one server fails, the remaining servers continue serving traffic. Load balancer health checks automatically detect server failures and remove unhealthy servers from the traffic rotation. Database failover through managed database high availability or manual replica promotion provides database-level resilience.
Designing for failure assumes that any infrastructure component can fail and implements redundancy at every layer: multiple application servers behind load balancers, database replicas with automatic failover, redundant load balancers, and multi-region deployment for geographic resilience. This defense-in-depth approach ensures that individual component failures do not cause application outages.
Scaling Patterns and Anti-Patterns
Common scaling patterns include: the scale cube (X-axis: horizontal duplication, Y-axis: functional decomposition, Z-axis: data partitioning); the sidecar pattern (auxiliary services deployed alongside primary services); and the circuit breaker pattern (preventing cascade failures when downstream services are unavailable). Understanding these patterns helps architects design scaling architectures that handle failure gracefully while maintaining performance under load.
Common scaling anti-patterns include: premature scaling (adding complexity before it is needed); scaling without monitoring (scaling blind without understanding actual bottlenecks); and ignoring database scaling (scaling application servers while the database remains a bottleneck). Avoiding these anti-patterns ensures that scaling efforts address actual capacity constraints rather than introducing unnecessary complexity.
Storage Scaling
Horizontally scaled applications require shared storage solutions that all instances can access. Approaches include: object storage (S3-compatible storage for media files and static assets); network file systems (NFS or managed file storage for shared file access); and database-backed file management (file metadata in the database with files stored in object storage). For WordPress specifically, plugin solutions like WP Offload Media seamlessly enable storing WordPress media files in object storage, ensuring media access from any server instance.
Monitoring and Capacity Planning
Effective scaling requires comprehensive monitoring that provides visibility into resource utilization trends and capacity thresholds. Key metrics include: CPU utilization (sustained levels above 70-80% indicate scaling need); memory utilization (consistent utilization above 85% suggests scaling); response time (increasing response times indicate capacity constraints); and request queue depth (growing queues indicate insufficient processing capacity).
Strategic capacity planning uses historical metrics and trend analysis to predict future resource requirements. Trend analysis of traffic growth, seasonal traffic patterns, and planned business events enables proactive scaling decisions rather than reactive responses to capacity crises. Load testing with tools like Apache JMeter, k6, or Locust validates that the infrastructure handles projected traffic levels before actual demand arrives.
Cost Optimization in Scaling
Scaling introduces cost considerations that require active management. Auto-scaling with maximum instance limits prevents runaway costs during traffic spikes or attack scenarios. Reserved instances or committed use discounts reduce costs for baseline capacity that remains constant. Spot or preemptible instances provide cost-effective burst capacity for fault-tolerant workloads. Right-sizing analysis ensures instances are not over-provisioned with resources that remain consistently unused. Regular cost reviews identify optimization opportunities as workload patterns evolve.
Summary
Cloud server scaling through vertical and horizontal expansion methods provides the foundation for building applications that handle growing demand while maintaining performance and availability. Vertical scaling provides simplicity for initial growth, while horizontal scaling provides the capacity, redundancy, and flexibility needed for production applications that outgrow single-server limitations. Effective scaling combines both approaches with load balancing, database scaling, caching strategies, and monitoring to create infrastructure architectures that grow efficiently with application demand.
For organizations beginning their scaling journey, the recommended phased approach is: thoroughly optimize the current server configuration first, then vertically scale when optimization is insufficient, then implement horizontal scaling with load balancing when vertical scaling reaches its limits, and finally implement intelligent auto-scaling policies for automated resource management at production scale.
Technical approaches and best practices discussed in this guide reflect current cloud infrastructure capabilities. Specific implementation details vary by cloud platform and application technology stack. Okut Hosting is an independent review platform providing educational hosting content.
For related guides, see our VPS management tools guide, our cloud backup strategies guide, and our managed vs unmanaged VPS comparison.